
Mar. 31, 2026
Work on Humanoid Robots and Reinforcement Learning
At Toyota Motor Corporation's Frontier Research Center, we are conducting research on AI-based control approaches to bring humanoid robots into practical use in society. We interviewed Takahiro Ito and Mitsuki Morita, who are conducting research on motion control for humanoid robots using reinforcement learning, about their research.
Overview
- First, could you briefly explain reinforcement learning?
- Ito
- Reinforcement learning is a type of machine learning in which an AI repeatedly attempts certain actions in an environment and autonomously discovers strategies that maximize a predefined reward. Recently, a method called "Sim2Real" has become popular in which robots are trained extensively in simulation environments, and the results are then applied to real robots. Because the simulation can expose the robot to a wide variety of conditions and situations, we expect the robots to perform well in the real world.
- What tasks did you work on this time?
- Morita
- Using the test platform we developed, we focused on learning two behaviors: walking and basketball dribbling. Walking is a fundamental behavior for humanoid robots, and we are considering dribbling for application to the AI basketball robot "CUE*1" that we are researching.
-

- The test platform used in this experiment
Training in simulation (left) and evaluation on the physical robot (right)
Challenge: the walking task
- What kind of reinforcement learning did you apply to humanoid walking?
- Ito
- For walking, we set rewards such as "bonus for walking near a target speed" and "penalty when a foot slips." In simulation, the humanoid robot learned walking through trial-and-error. During training, we run thousands of robot instances in parallel in the simulator to speed up learning. Within about one to two hours of training, the robots learned to balance and walk. After training stable forward, backward, and turning motions in simulation, we applied the results to the real robot and verified walking stability. Achieving immediately stable walking on the real robot was difficult, but by gradually refining the behavior on the hardware, we were finally able to achieve successful walking.
- Multiple simulated robots learning to walk using reinforcement learning
- What difficulties did you encounter?
- Morita
- We struggled with the so-called "Sim2Real gap," where robot behavior differs significantly between simulation and hardware. To enable stable real-world performance, we applied several strategies. Specifically, we used "Domain Randomization"―adding noise to encoder (joint rotation) and IMU (orientation/motion) sensor readings and randomizing floor friction to replicate environmental variability. We also worked on "Real2Sim," optimizing the simulator's actuator model based on data collected from operating the real actuators (motors, etc.) to align simulated and real behavior. These strategies proved effective.
-
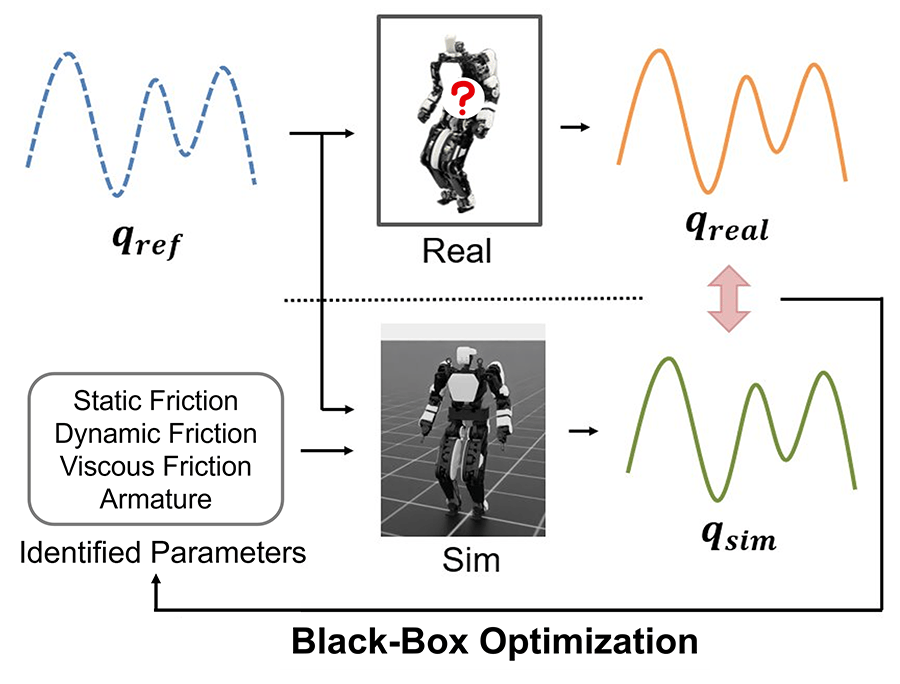
- Real2Sim: optimizing the simulation's actuator model to match real robot data
Using black-box optimization, we identify the joint parameters in the simulator (static friction, dynamic friction, viscous friction, and inertia) so that the actual joint-angle trajectories in response to commanded joint angles match those of the real robot
- Morita
- Another important point was verifying that the behaviors learned in simulation were feasible on the real robot. For example, a gait might look stable in simulation but actually rely on oscillatory control commands, shuffling feet, or abrupt leg movements that are hard to reproduce on hardware. For every new walking model we trained, we tested it on the real robot; if it failed, we formed hypotheses, applied countermeasures, retrained, and tested again. By repeating this cycle, we gradually achieved stable walking on the real hardware. Achieving walking on the real robot turned out to be much more difficult than stable walking in simulation.
- Walking experiment demonstrating balance recovery under external perturbations
Challenge: the dribbling task
- Next, about dribbling. What's the difference between dribbling and walking in robot control?
- Ito
- Dribbling requires manipulating an external object―the ball―in addition to controlling the robot's own motion. Because the ball is constantly moving during dribbling, the robot must accurately model the ball's dynamics and coordinate its own movements accordingly. The timing constraints for contact with the object are also fundamentally different. Specifically, when walking, the robot can largely choose when to place its foot on the ground, but in dribbling, contact with the ball is brief and highly time-constrained, making action selection much more challenging.
- It sounds difficult because you must precisely synchronize the ball's motion and the robot's movement at momentary events. How did you design the reinforcement learning rewards?
- Morita
- Designing rewards for dribbling was much harder than for walking. For walking, there is a wealth of prior research to reference and rewards can be designed mainly around the robot's body motion. Dribbling, however, requires evaluating actions more precisely: launch speed and direction of the ball, and continuous control to maintain contact with the ball. Defining quantitative metrics for these and giving appropriate rewards is difficult. Hand-designed rewards also tended to produce unnatural dribbling motions. Furthermore, continuously tuning rewards by hand, as we had done during walking development, was time consuming and problematic.
- How did you address that problem?
- Ito
- We adopted a method that leverages human motion data. We recorded humans dribbling with motion capture and converted the captured joint angles and motion velocities to match the robot's skeleton and joint ranges. These converted motions were used as reference data for the robot to imitate and they were trained with a reward that increased as the robot's motion approached the reference. This allowed the robot to learn natural, stable motions without requiring many specific evaluation metrics. We also extracted the timing of ball contact from the human data, so the robot learned to contact the ball at appropriate moments. As a result, we achieved dribbling that is both reproducible on the real robot and natural like a human's dribble.
- Dribbling training pipeline
- What Sim2Real difficulties did you face for dribbling?
- Morita
- The biggest challenge was the gap in ball perception. In simulation, the ball's position and velocity can be obtained directly with perfect accuracy, but on the real robot they must be estimated using a camera and recognition algorithms. Accurate perception is crucial during dribbling, so recognition errors and estimation latency had a large impact. Consequently, behaviors that worked in simulation often failed on the real robot, reducing Sim2Real success rates. To address this, we evaluated camera recognition errors and latency in a real environment using motion capture and incorporated these characteristics into the simulator to produce more realistic observations. This made dribbling on the real robot successful.
- The real robot dribbling; it recognizes the ball with a head-mounted camera
- What are your future plans?
- Ito
- We are now working to bring the dribbling behavior validated on our test platform to CUE. Our first step is to deploy the newly developed learning framework, refining it until we achieve stable, real-world performance. From there, we will focus on capturing the dynamic energy of a professional basketball player. We'll work hard to soon be able to show CUE playing basketball with the same dynamism as a basketball player.
- Morita
- We will focus our research on a general-purpose control framework for humanoid robots that can handle a wide range of tasks and adapt flexibly to diverse situations, combining not only reinforcement learning but various other technologies. While global technology is advancing rapidly, we aim for a future in which humanoid robots standing beside people are commonplace as soon as possible, and we will continue our research with a strong sense of urgency to lead the way.
Authors
-

- From the left: Morita and Ito
Takahiro Ito
Humanoid Robot Research Group, R-Frontier Div., Frontier Research Center
Joined Toyota Motor Corporation as an experienced hire in November 2024.
Mitsuki Morita
Humanoid Robot Research Group, R-Frontier Div., Frontier Research Center
Joined Toyota Motor Corporation as a new graduate in 2024.
Contact Information (about this article)
- Frontier Research Center
- frc_pr@mail.toyota.co.jp
RELATED CONTENT
MOST POPULAR




