
2024年03月29日
ラフなスケッチでロボットを遠隔操作する!?~人とロボットの新しいインタラクションとは~

トヨタ自動車株式会社 未来創生センター(以下、トヨタ)では、すべての人に移動の自由を提供することを目指し、人と共存するロボットの研究に取り組んでいます。近年の自然言語処理や画像生成など、さまざまなタスクに適用できる機械学習手法の発展により、ロボット単体やロボットシステム全体の性能が急速に向上しています。今回は、ロボットと人が協調、協働するために、操作者がより直観的な指示をロボットに与えるインタフェースの研究をしているメンバー、岩永と棚田に話を聞きました。
2012年から提案している自律と遠隔を組み合わせたロボットシステム
-ロボットの研究と言うとロボット自体の機能や性能に目がいきがちですが、遠隔操作の研究を始めたきっかけを教えてください
- 岩永
- トヨタは、2012年に生活支援ロボットの研究プラットフォームHSR(Human Support Robot)を発表し*1、世界中の研究者との共創研究*2(2023年4月よりその運営を日本ロボット学会に移管。現在は10か国57機関が参加)や家庭内、施設などでの実証実験を進めてきました。トヨタはHSR開発当初から、ロボットの自律的な機能と人による遠隔操作を組み合わせたロボットシステムを作ることが重要だと思い、取り組んできました。遠隔操作でシステムに人が介在することで、自律的に動くロボットが苦手とする未知の環境や物体のハンドリングも、人の認知判断能力で補助することが可能になります。また、東京2020パラリンピック競技大会ではトヨタループス株式会社と共同で、愛知県豊田市から東京のスタジアムにあるHSRを多台数遠隔操作してサービスを提供しました*3。二人三脚で開発を進めてきたオペレータの方から、「障がい者の職業選択において、事務職などのデスクワーク以外は諦めて生きてきたので、ロボットを介すことで接客という道があるなんて」と、驚きや感動を伝えていただいた経験は私の中でとても大きく、ロボットの遠隔操作は、操作者の可能性も広げることができる技術なのではないかと考えています。
-ロボットの遠隔操作はどんなところに難しさがあるのですか?
- 岩永
- ロボットは、移動するための車輪、いくつもの関節から構成されるアームやハンド、視界を確保するためのカメラなど、多くの機能を有しています。操作者は画面越しに遠隔地にいるロボットの映像を見ながら、それらを操作しているので、実は少ない情報をもとに多くの操作をしているんです。いかに簡単に、かつ、操作者の思い通りにロボットを動かすことができるかが、研究のキーとなります。
-なるほど。長時間の操作の練習をしなくても誰もが「簡単」「思い通り」にロボットを動かせられると、バーチャルな移動が広がりますね
- 岩永
- そうですね。私たちは、あらかじめ決められたシナリオやプログラムされた動きの選択や実行ができるだけではなく、操作者が自身の思った通りにロボットを動かすことができてこそ遠隔操作の価値が高められると考えています。同時に、その実現のために操作者が大きな負担を負うことは望みません。もちろんユースケースによって適切なインタフェースは変わりますが、2021年から始まったこの研究では、いつでもどこでもだれでも簡単かつ思った通りにロボットを遠隔操作して物理的な作業を指示する手書きインタフェースをコンセプトに掲げています(動画1)。
- 動画1 スケッチインタフェースの動作説明
スケッチインタフェースの概要
-まず、スケッチでロボットを操作するとはどういうことですか?
- 岩永
- 人が誰かに何かを伝えるとき、手書きの図形や絵を使うことがあると思います。これを、誰もが簡単にロボットに意図を伝える手段としても適用できるのではないかというのがアイデアです(2019年特許出願済み*4)。実際に、平面の地図に手書きの線を描いてロボットの平面移動経路を指示するような研究が先駆けとしてあります*5が、三次元の動きをするロボットアームを二次元のスケッチインタフェースで操作する事例は、プロジェクト開始当初はありませんでした(当社調べ)。最近はロボットアームの軌跡をスケッチで表現し、自律ロボットの学習システムにおける汎化能力(学習された知識やスキルを新しい状況や問題に適用できる能力)の獲得を試みた研究も出てきており*6、言語だけでなくスケッチで操作者の意思を伝えるということの重要性が認知されてきたと感じています。
-スケッチで伝えることのメリットは具体的にどういったことがあるのでしょうか?
- 岩永
- 日常生活で物を持ったり運んだりするときを想像してみてください。人は無意識に、物のどの部分を持つとよいのか、状況や自分のニーズに合わせてその対象物を握りますよね。例えば、歯ブラシならば柄を持ちますし、お皿が汚れていたらそこに触れないようにつかみますし、野球帽をつかむときはつばを持った方が後々帽子掛けにかけやすいなどです。アフォーダンス*7とも近い考え方ですが、人が普段無意識に「こうしたい」「こうした方がいい」と感じることを、ロボットにもラフな線や記号で非常に簡単に伝えられることがスケッチのメリットです。
プロトタイプの実装とユーザー評価で見えた課題
-技術的にはどのように実現したのでしょうか?
- 岩永
- まずは、ロボットの視点を変更する、移動する、物をつかむという3つの基本機能を開発しました(動画2、3、4)。まず「ロボットの視点変更」ですが、操作者は、タブレットに映ったロボット搭載のカメラがとらえた映像(以下、カメラ映像)だけを見ながらロボットを操作します。操作者がタブレット画面上にペンを自由自在に動かしながらロボット搭載のカメラの向きを変えられるように、視点変更機能を実装しました。次に「移動」についてですが、操作者は映ったカメラ映像の地面上に線を引いて、ロボットを動かしたい経路を指示します。そうすると画像上に描かれた線に対して、RGBDセンサー(カラー画像と距離画像を取得できるセンサー)情報から三次元位置データを取得し、ロボットに移動指示を出します。最後に「物をつかむ」ですが、これは一番苦労したところです。まず、画面上でつかみたい物体の周辺に、ロボットのハンドの形を模擬した「コの字」を描いて、どのようにつかみたいかを伝えます。そうすると画像からコの字の位置と向きを抽出し、RGBDセンサーから得られる距離情報から物体と置いている環境との境界点を探し、三次元の物体をつかむ位置を算出します。つかむ向きは、環境と物体を固定してシミュレータ上で学習データを作成し、学習モデルで推論するようにしました(図1)。
-
- 動画2 視点変更の様子
-
- 動画3 移動の様子
-
- 動画4 物をつかむ様子
-

- 図1 物体をつかむ向きを推定する学習モデル
-実際に使ってみてもらった感想はどうでしたか?
- 岩永
- トヨタ内の20代から50代の10名の被験者に缶を3つ拾うという遠隔操作をスケッチインタフェースで行ってもらいました*8。結果は、操作自体は直観的で楽であった、ロボットが動き出せば自分のイメージ通りであったという期待通りの意見をもらえたものの、物をつかむ機能については大きく2つの課題が見つかりました。1つ目は、操作者が文字通り「自由」には指示ができないことです。操作者の指示をシステムが理解しやすいように設けた描き方のルールが、逆にユーザーの制約になってしまっていたのが原因でした。2つ目は、操作者の意図とロボットが推定するその動作の実現可能性のどちらを尊重するか、つまり「調停」するかということです。操作者が誤った指示を出したときにロボットがそれを信じて動いてしまうと、タスクの成功率や達成時間に悪影響を及ぼします。操作者の意図を尊重しつつも、ロボットの自律的な機能も活用して、システム全体のパフォーマンスを高めることが重要だと分かりました。
スケッチで描かれた操作者の意図を解釈する技術とは
-1つ目の、操作者が自由に指示ができない課題に対してはどのように解決を試みているのでしょう?
- 棚田
- 最新の生成AI技術を活用して解決を試みています。近年Vision-Language Model(以下、VLM)と言って、ChatGPTのような言語モデルを自然言語だけでなく画像入力にも拡張したモデルが、画像のキャプショニングや視覚的推論などで高い性能を示しています*9。そこで、指示内容を描いた画像と、事前に設計しておいたプロンプト(モデルに与えられる入力としてのテキスト)を入力し、操作者の指示を理解しロボットの動作を生成するモデルを構築しました(図2)。あらためて動画1をご覧ください。
-
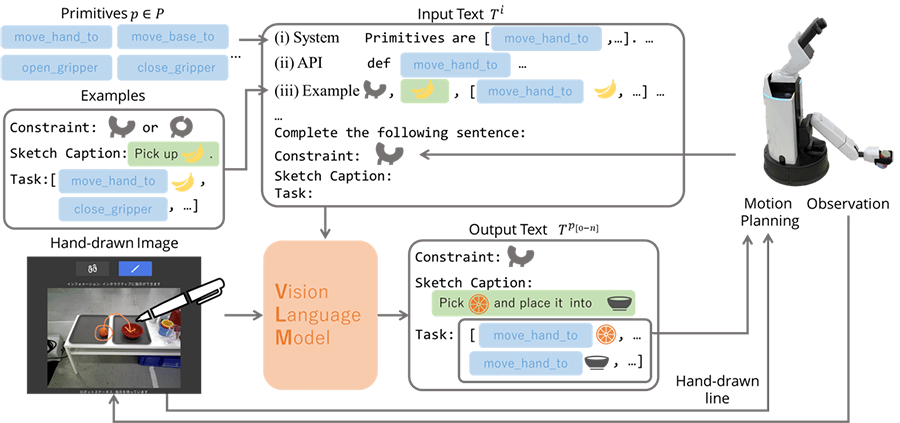
- 図2 VLMを使ったスケッチの意図解釈モデル
-VLMを使うとどのようなことができるようになったのでしょうか?
- 棚田
- 今までは「移動する」「物をつかむ」は同時に指示することができず、指示入力画面を切り替えて動作ごとに指示が必要でしたが、VLMが一括して解釈してくれるようになりました。例えば、同じ「線を描く」指示でも地面の上に描いたらVLMがロボットの移動指示と理解しますし、リンゴからボウルに向かう線を描くとロボットがリンゴのおいてある場所まで移動し、リンゴをつかみ、ボウルの中に入れるという指示と理解してくれるイメージです。後者のように、移動し、物をつかんで置くというような複数のタスクの組み合わせも一回の指示で表現できるようになりました。これは、今までより柔軟に操作者の意図を解釈してくれる賢いロボットの実現につながる技術だと考えています。
-プロンプトの工夫など、おもしろい技術が詰まっていそうですね
- 棚田
- ありがとうございます。この成果は2024年度人工知能学会全国大会(人工知能学会主催、5月28~31日開催)で発表予定です。
「半自律」でロボットを操作すること
-2つ目の、操作者の意図とロボットの自律的な機能の調停というのはどうやって実現していくのでしょうか?
- 岩永
- 人とロボットの間で制御を共有するShared Controlという考えが古くから研究されていて*10、人とロボットの協調、協働には欠かせない考えだと思っています。私たちも、環境や状況、そして人の意思から総合的に判断するロボットシステムの構築に挑戦していきます。例えば、物をつかむ機能に関しては、センサーの情報から物理的にその物体をつかむロボットのハンドの位置や姿勢の候補を大量に出力するような学習モデルが公開されています。この中から操作者の意図に近いものを選ぶというのはひとつの調停の形だと考えています。また、モデルからの回答が必ずしも操作者の意図に合うとは限りません。そこで、操作者がインタフェースを介してロボットとインタラクションし、より操作者の意図に近い答えを導けるような仕組みを今後研究していく予定です。
-自律的な機能と、操作者と協調するための遠隔操作技術、どちらの発展もロボットの研究には重要なのですね
- 棚田
- はい。双方の発展につながる研究のループが回せたらいいなと思います。例えば、私たちの開発するインタフェースで簡単かつ操作者の思い通りにロボットを操作できるようになれば、自律的な機能の性能向上に欠かせない学習データの収集にも役立つ可能性があります。トヨタには、自律ロボットの性能向上をテーマにしている仲間も多いので、実際に使ってもらったり意見をもらったりしながら研究を進めていきたいです。
今後の意気込み
- 岩永
- 警備や搬送、配膳ロボットなどを目にする機会も多くなり、ロボットの遠隔操作はますます身近な技術になってくると思います。今後は積極的に国際学会への投稿にも挑戦し、ロボットの社会実装に貢献できる技術を生み出したいです。
- 棚田
- ぜひたくさんの方に興味を持っていただき、仲間づくりができたら嬉しいですね。
著者

岩永 優香(いわなが ゆうか)
未来創生センター R-フロンティア部 協調ロボティクス研究グループ 主任

棚田 晃世(たなだ こうせい)
未来創生センター R-フロンティア部 協調ロボティクス研究グループ
参考資料
| *1 | トヨタ自動車、家庭内での自立生活をアシストする生活支援ロボットを開発 |
|---|---|
| *2 | 未来につながる研究 世界の研究者と“共創”で挑むロボット研究 |
| *3 | トヨタイムズ 東京2020を支えた技術と人 第2回 おもてなしロボット「HSR」 |
| *4 | トヨタ自動車株式会社、山本 貴史、遠隔操作システム及び遠隔操作方法、特開2021-94605、2021-06-24 |
| *5 | D. Sakamoto et al. Sketch and Run: A Stroke-based Interface for Home Robots. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI '09, page 197–200, 2009 |
| *6 | Jiayuan Gu, Sean Kirmani, Paul Wohlhart, Yao Lu, Montserrat Gonzalez Arenas, Kanishka Rao, Wenhao Yu, Chuyuan Fu, Keerthana Gopalakrishnan, Zhuo Xu, Priya Sundaresan, Peng Xu, Hao Su, Karol Hausman, Chelsea Finn, Quan Vuong, and Ted Xiao. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches, 2023 |
| *7 | J. J. Gibson (1966). The Senses Considered as Perceptual Systems. Allen and Unwin, London. |
| *8 | 岩永 優香、森 健光、土永 将慶、山本 貴史 : 2D手書き指示でロボットに人の意図を伝えるインタフェースの開発と評価~物拾いタスク指示手法に関するパイロットスタディ~, 第41回日本ロボット学会学術講演会予稿集, 1J1–03, 2023 |
| *9 | Rana, K., Haviland, J., Garg, S., AbouChakra, J., Reid, I., and Suenderhauf, N.: SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning, 2023 |
| *10 | M. Selvaggio, M. Cognetti, S. Nikolaidis, S. Ivaldi and B. Siciliano, "Autonomy in Physical Human-Robot Interaction: A Brief Survey," in IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7989-7996, Oct. 2021 |
本件に関するお問い合わせ先
- 未来創生センター
- frc_pr@mail.toyota.co.jp
関連コンテンツ
アクセスランキング




